
内存管理(二):高速缓存
高速缓存
程序和数据是存储在磁盘中的,由于访问磁盘的速度非常慢,所以在程序执行的过程中,需要将磁盘中的程序和数据加载到内存中。这样可以将内存看成磁盘的cache
虽然说内存比磁盘快很多,但是对于现在的CPU来说,访问内存还是太慢了。所以CPU里面还有高速缓存。
分层

- 越往上层,读写速度越快,成本越高,容量越小
为何这种层次是可行的
从硬件上:较慢的存储设备比较快的存储设备更便宜
从软件上:一个编写良好的程序应该具备良好的局部性
- 时间局部性:一个数据第一次被访问后,很可能在不久以后再次被访问
- 空间局部性:一个数据被访问以后,那么程序很可能在不远的将来访问这个数据附近的数据
访问过程
- 如果就寄存器中没有数据,去L1中读取,
- 如果不命中,则从L2中读取数据到L1
- 如果L2也不命中,则到L3中读取到L2
- 如果L3也不命中,则到主存中读取到L3
- 主存依然不命中,则到磁盘中读取数据到主存
注:缓存不命中到下一层取数据时是以数据块的形式拿数据的,一般一个数据块是4KB,因为空间局部性
定位高速缓存中的数据
缓存中的结构
- 将高速缓存分为S个组,一个组内有E个缓存行,一条缓存行包含:有效位、标记位、B个字节的缓存块
- 一个32位内存地址划分为:t位标记、s位组索引,b位块偏移
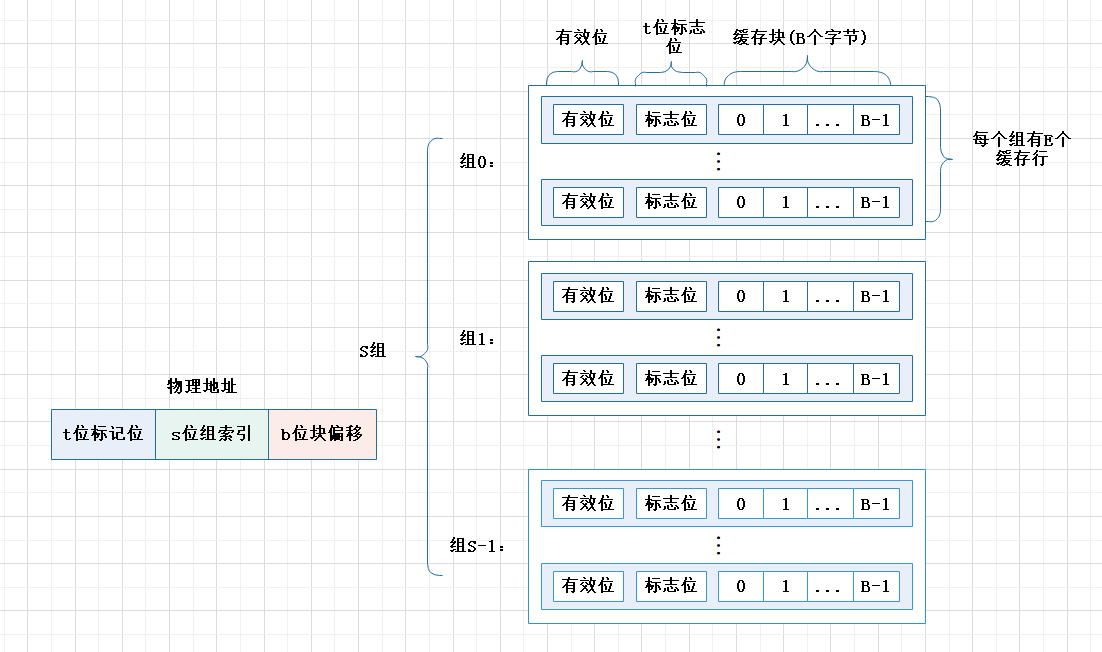
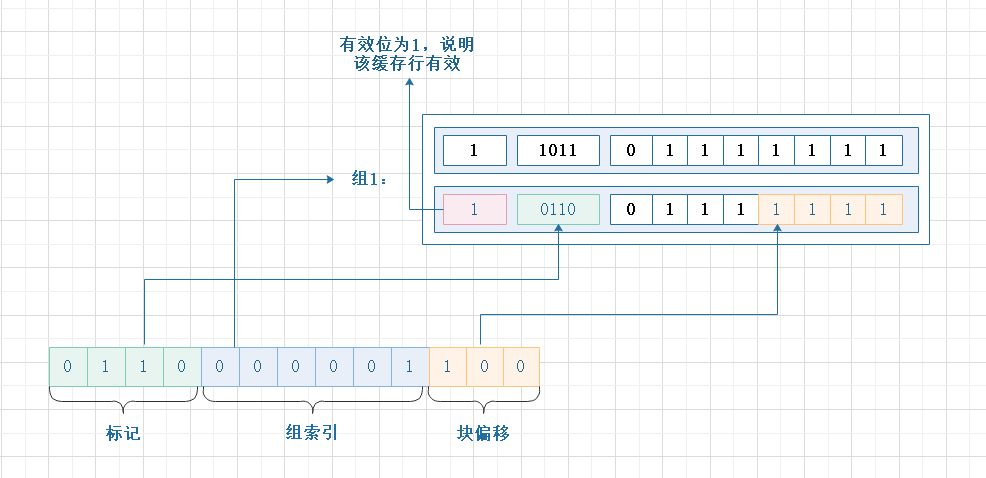
如何定位
- 根据地址中的s位组索引找到数据在第几组
- 遍历组内每一行
- 检验缓存行有效位是否为1
- 校验标志位匹配,如果匹配则说明缓存命中
- 然后通过块偏移从块中读取数据
高速缓存的命名
如果E = 1,即一个组内只有一个缓存行,则称:直接映射高速缓存
如果1 < E < C/B,即一个组内有多个缓存行,则称:组相联高速缓存
E = 2:称为2路组相联高速缓存
E = 3:称为3路组相联高速缓存
如果E = C / B,则称:全相联高速缓存
行替换和行更新
行替换
如果高速缓存中没有数据,且该组中的所有行数据都是有效的。那么我们需要选择一行数据替换出去。
可以使用局部性原理:
随机替换
LFU:访问次数最小的,将访问次数最少的行替换掉
LRU:最近最少使用,将最后一次访问时间最久远的行替换掉
行更新
比如CPU需要向内存中写数据,即需要把高速缓存中的数据同步到内存中。有两种方法,一种是写直达,一种是写回
写直达
- 对于要写入的数据如果缓存不命中,直接写入主存
- 如果缓存命中,将数据写入缓存块,然后再将数据写入主存
这种方式比较简单,但是由于每次写数据的时候都需要经过内存总线,速度很慢。
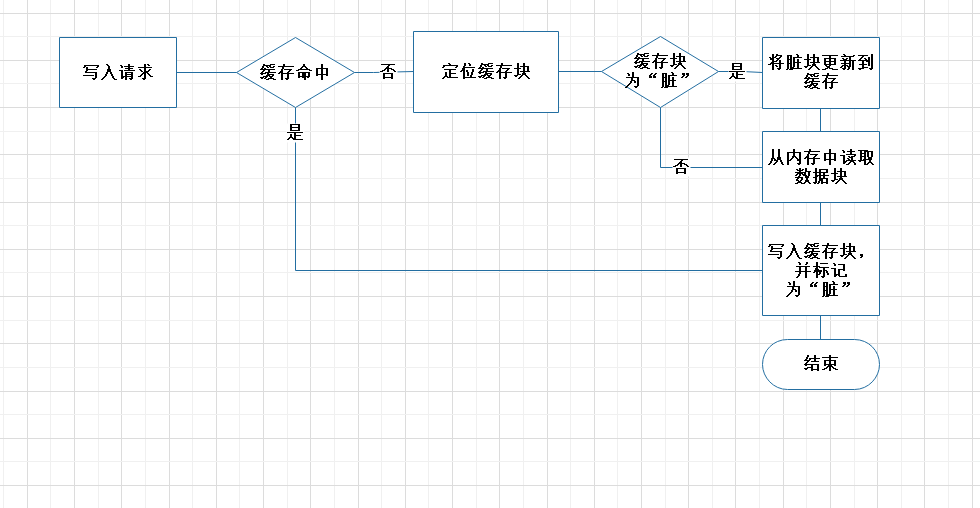
写回
主要的思想是推迟更行,等到替换算法需要去驱逐这个“脏”缓存块的时候,才将数据写入内存。由于局部性原理,可以减少总线流量。
- 对于要写入的数据,如果缓存命中,将数据写入缓存块,并标记为“脏”
- 如果缓存不命中,则定位缓存块
- 如果定位到的要被替换的缓存块为“脏”,则将该“脏”数据块写入内存。然后从内存中读取缓存不命中的数据,并将要更新的数据写入缓存块中,并标记为“脏”
- 如果缓存块不是“脏的”,直接从内存中读取数据到缓存中,将数据写入缓存块,并标记缓存块为“脏”
高速缓存性能指标
性能指标
- 不命中率:不命中次数/总访问次数
- 命中率:1 - 不命中率
- 命中时间:高速缓存传送一个数据到CPU的时间,包括组选择,行确认,缓存块偏移选择时间
- 不命中惩罚:由于不命中所需要的额外时间
成本和性能的折中
- 高数缓存大小的影响
- 大的高速缓存块可以提高命中率,但是同时也会提高命中时间
- 缓存块大小的影响
- 大的缓存块可以尽可能的利用空间局部性,帮助提高命中率。但是如果缓存大小已经确定,大的缓存块会使得缓存行减少,会损害时间局部性比空间局部性好的程序的命中率。
- 现代操作系统一般会选择64字节作为缓存块大小
- 相连读的影响
- 较高的相连度可以降低由于冲突不命中出现抖动的可能。不过,较高的相联度会造成较高的成本,且速度很难变快,因为要搜索很多缓存行。
TLB高速缓存
CPU每次访问内存中的数据都需要两次访问内存:
- 第一次将虚拟地址转换为物理地址,需要访问内存
- 第二次用物理地址去内存中加载相应数据
TLB是块表,用于缓存页表项(PTE),减少一次访问内存时间。MMU读取页表项的时候,不会先去访问主存,而是先到TLB中找这个页表项,如果不在TLB中,再去主存中读取。
- TLB 硬件和 CPU 的高速缓存一样,不过TLB通常具有较高的相联度,即每个组中含有多个缓存行
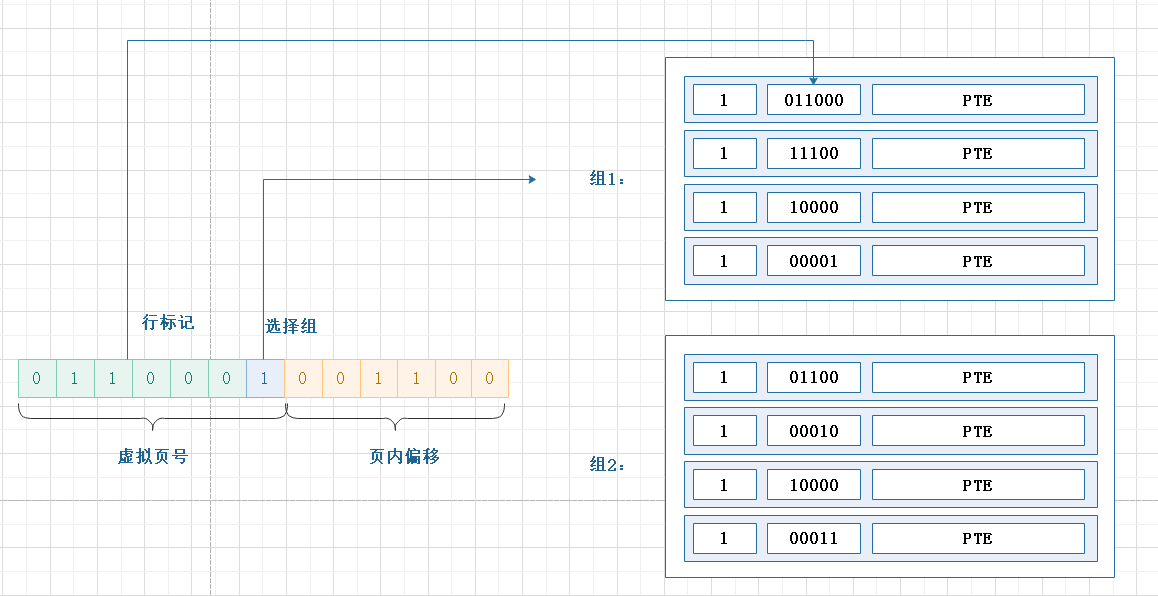
- 不需要块偏移,因为缓存的就是PTE,直接获取即可
含有TLB以后如何访问页表
CPU先将虚拟地址给到MMU,MMU通过虚拟地址中的虚拟页号到TLB中读取页表项
- 如果命中,TLB返回页表项给MMU
- 如果不命中,MMU需要到内存中的页表读取PTE,拿到PTE以后会缓存到TLB,并返回给MMU。
cpu缓存结构
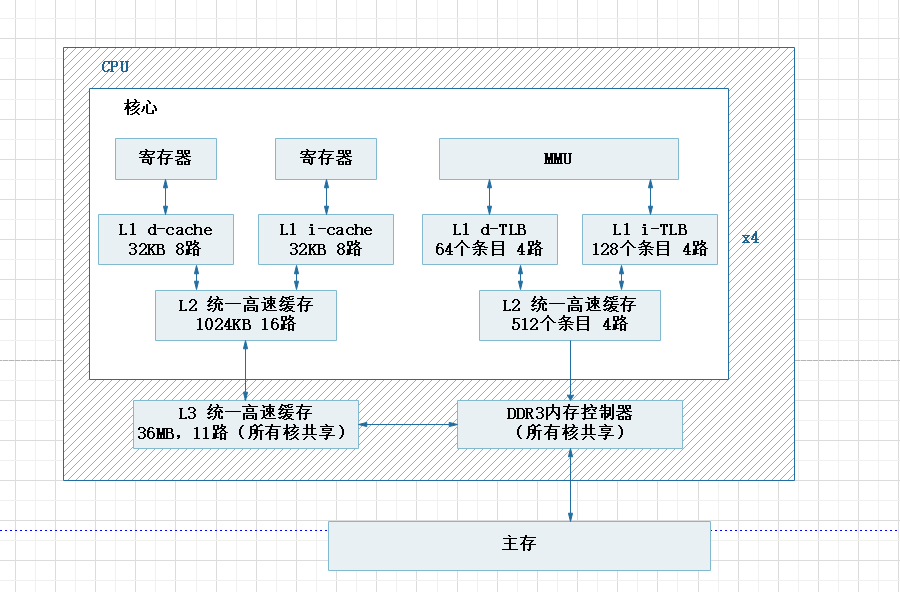
- L3统一高速缓存,所有核共享的
- DDR3内存控制器,所有核共享
L1 d-cache对应L1 d-TLB,L1 i-cache对应L1 i-TLB。每个L1 cache都会有一个L1 TLB与其对应





